Motivation & Objectives
Most existing active-sensing guided-wave methods are based on the requirement that a relatively large data set can be collected, and thus are not feasible when data collection is restricted by time or environmental conditions. Meanwhile, simulation results, though lack of accuracy compared to real world data, are easier to obtain. In this context, models that incorporate data from different sources have the potential to embrace the accuracy of experimental data and the convenience of simulated data without the necessity of large and, potentially costly experimental, data sets.
Main Contributions
The goal of this work is to introduce and assess a probabilistic multi-fidelity Gaussian process regression framework for damage state estimation via the use of both experimental and simulated guided wave signals. The main differences from previous works include:
(1) Utilizing damage-sensitive features (damage indices; DIs) extracted from experimental and numerical sources as inputs to Multi-fidelity GPRM;
(2) Multiple tasks were examined to prove the outperformance of Multi-fidelity GPRM over standard GPRM;
Method of Approach
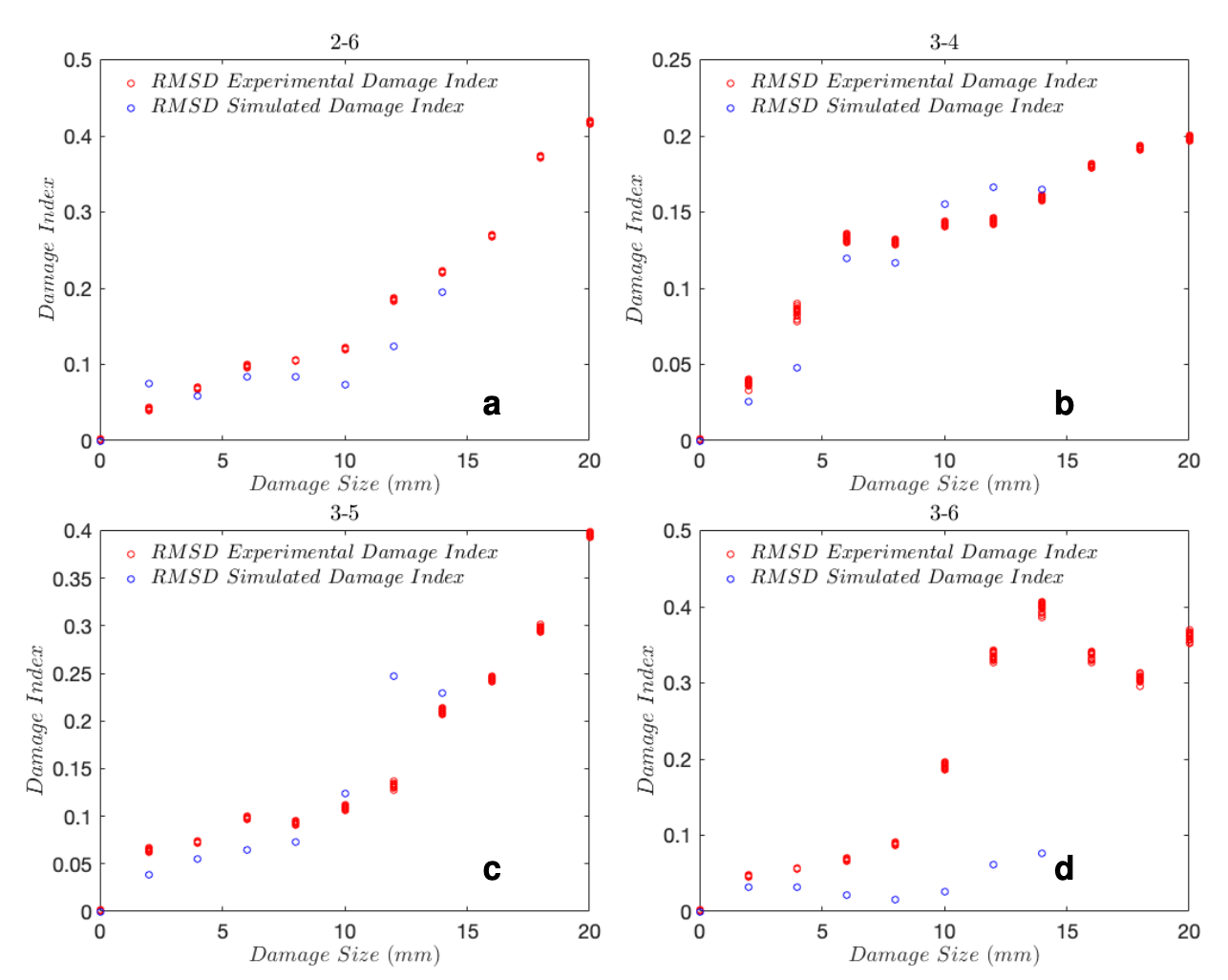
Feature (DI) extraction from pre-processed signals
- Multi-fidelity GPRM implemented on extracted DI from various sources
- Comparison between standard Gaussian process regression model (GPRM) and the proposed multi-fidelity GPRM under various tasks
Indicative Results
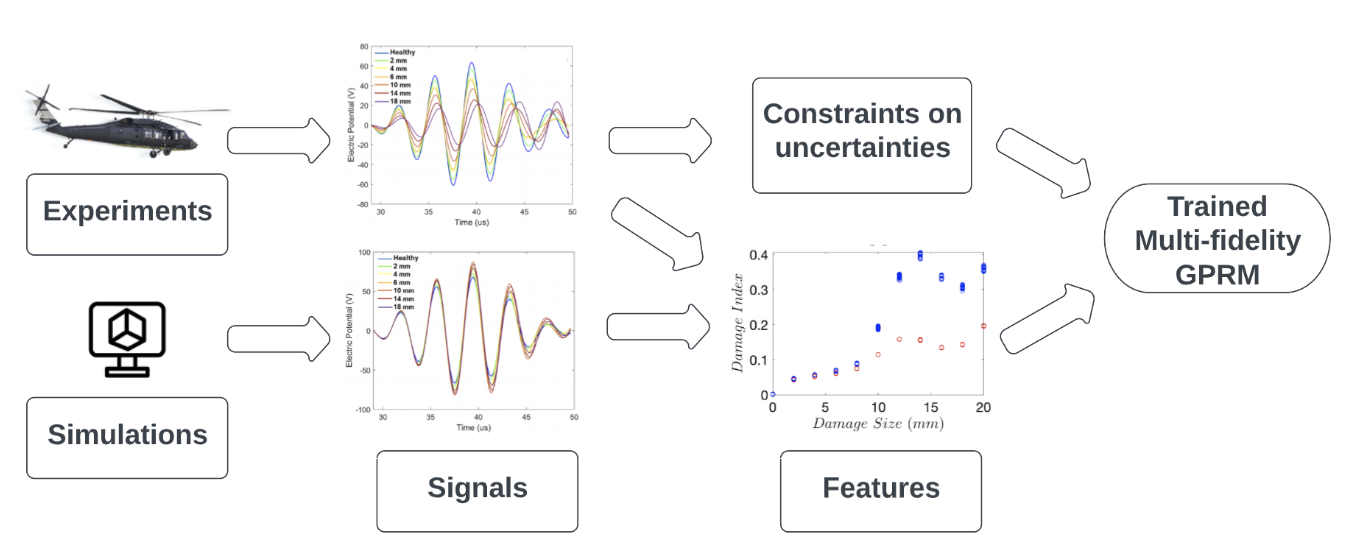
Figure 1 schematically depicts the framework of implementation and comparison of the proposed
model with the conventional one. Data preprocessing is applied on signals from various sources first
to reduce the noise effect. About 75% of them are then treated as training set from which features
are extracted and then fed into the regression models as inputs. For the rest of the 25% DIs, those
from the experiments with a higher fidelity are treated as testing set after being extracted from
signals therein. It is worth noting that, standard GPRMs only accept data from single source while
multi-fidelity GPRMs accept multiple sources, so the two types of models have different training
set while sharing the same testing set.
training procedure.
Task 1: Fixed experimental data size while increasing simulated data
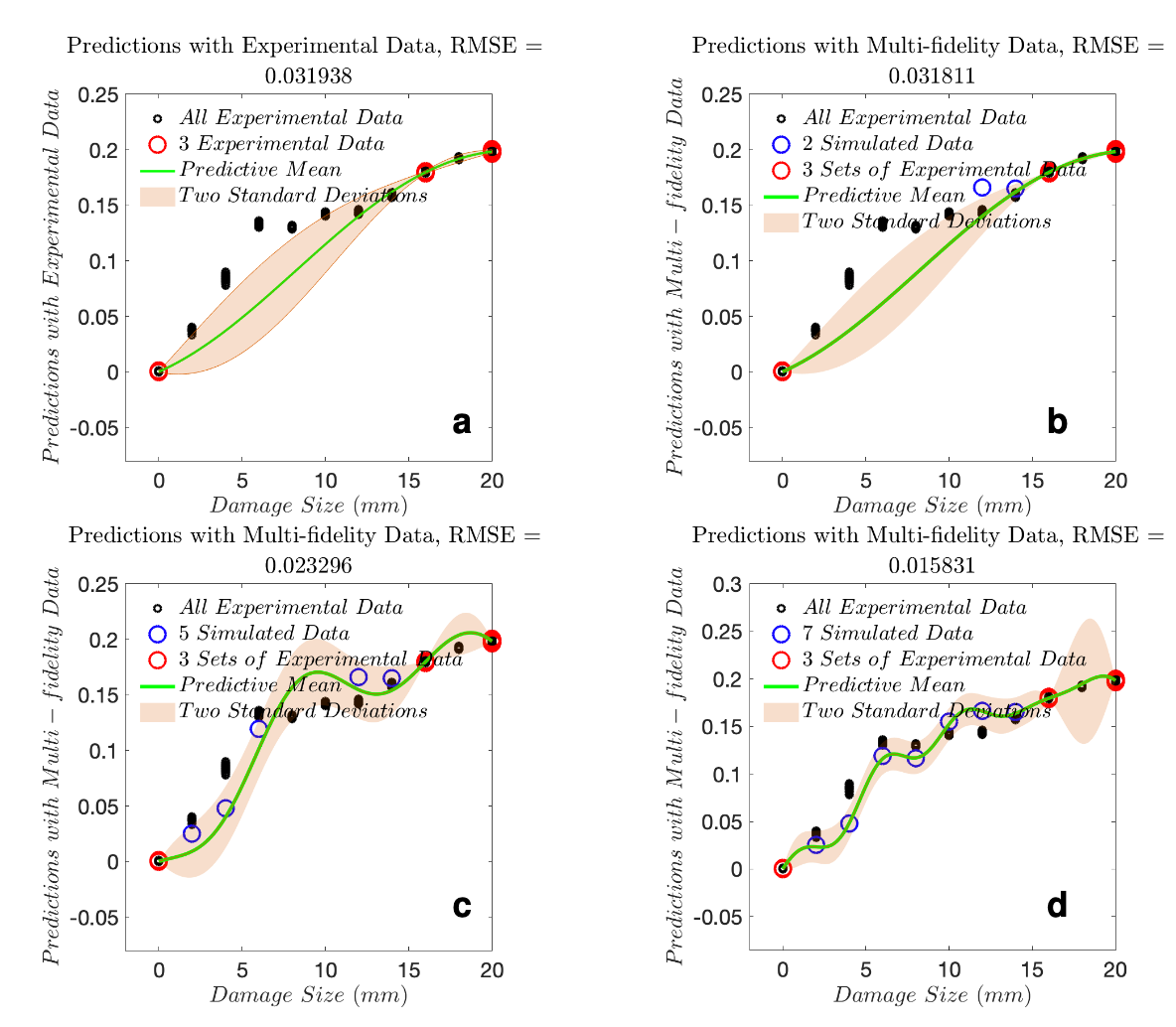
3 experimental sets at 0, 16 and 20 mm; (b) prediction using 3 experimental sets and 2 simulated
data points; (c) prediction using 3 experimental sets and 5 simulated data points; (d) prediction
using 3 experimental sets and 7 simulated data points.
Task 2: Fill the data-sparse region by simulated data
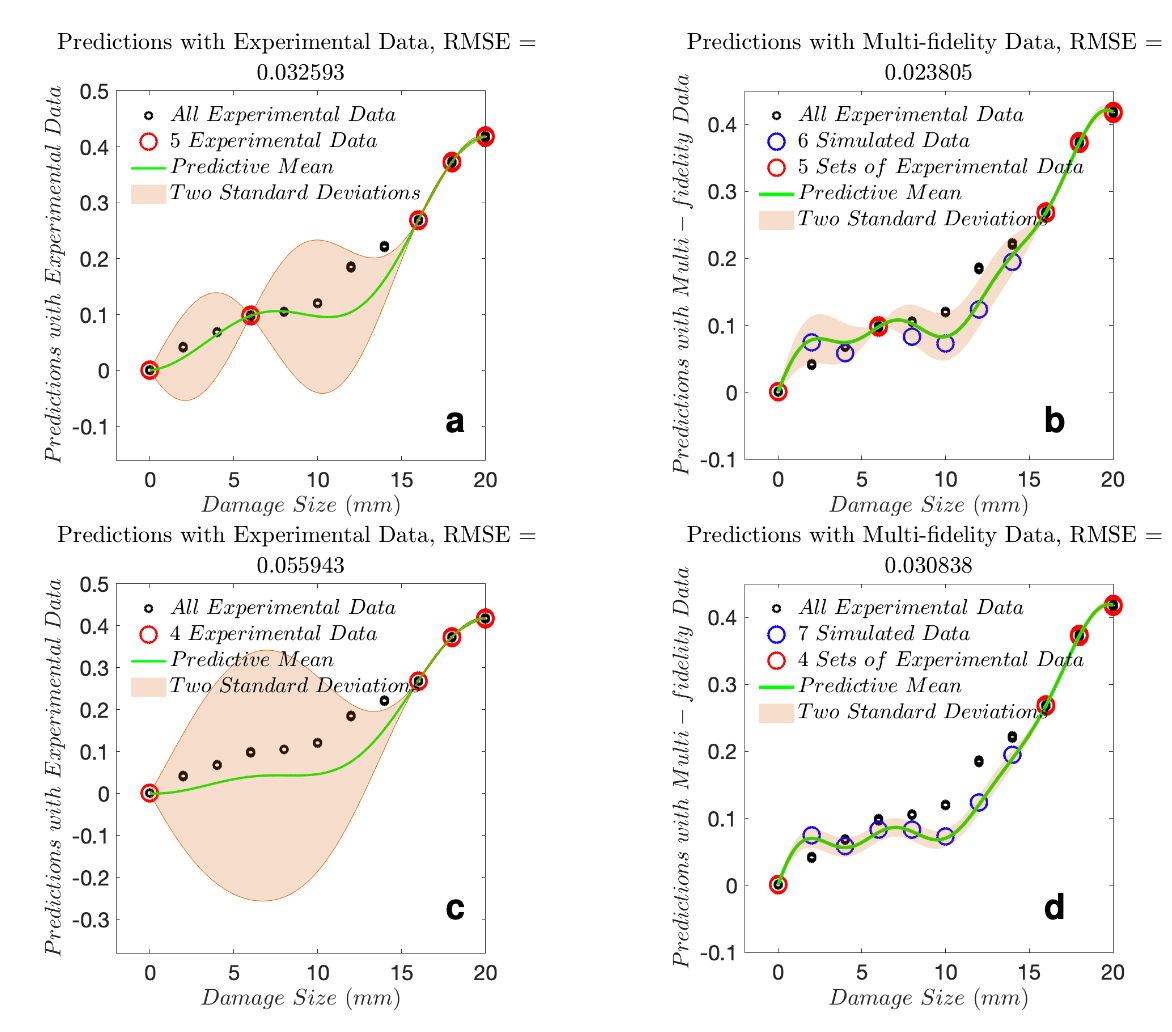
5 experimental sets at 0, 6, 16, 18 and 20 mm; (b) prediction using 5 experimental sets and 6
simulated data; (c) prediction using 4 experimental sets at 0, 16, 18 and 20 mm; (d) prediction
using 4 experimental sets and 7 simulated data
Task 3: Combination with active learning
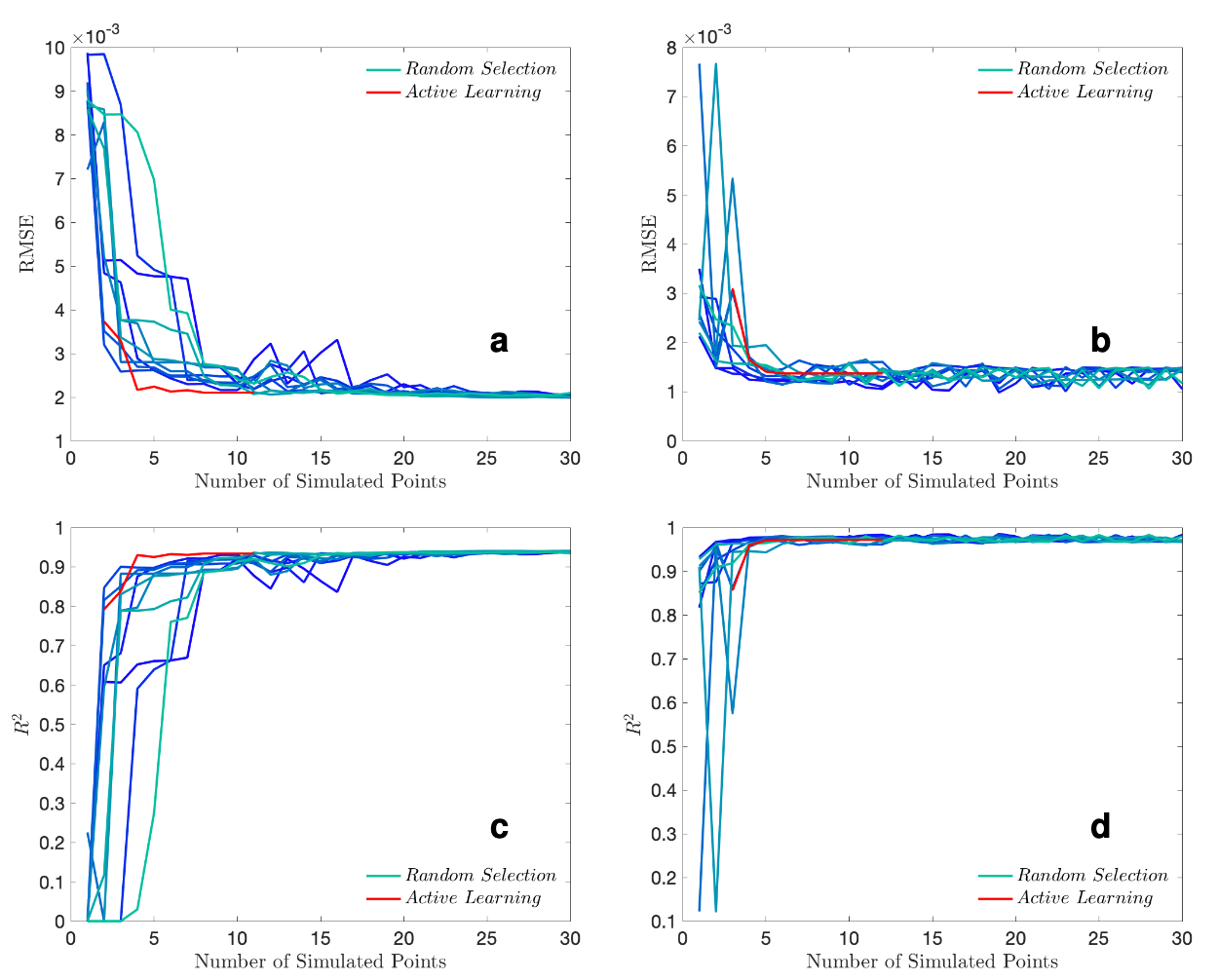
experimental sets are 2 and 3 respectively. Panel c and d are corresponding the 𝑅2 values with
respect to number of iterations. The graduated blue curves correspond to batch learning with
random selection while the red curve corresponds results from active learning.